一、NCBI数据库简介
NCBI,全称为美国国家生物技术信息中心(National Center for Biotechnology Information),是美国国立卫生研究院(National Institutes of Health)的一个部门。NCBI成立于1988年,旨在促进生物医学研究,通过收集、存储和提供生物医学信息来加速科学和健康进步。
NCBI提供多种数据库和工具,用于研究遗传学、分子生物学和生物信息学等领域。其中最著名的数据库包括GenBank(一个公开的核酸序列数据库)、PubMed(一个医学文献数据库)、Protein(蛋白质序列数据库)和SNP(单核苷酸多态性数据库)等。
NCBI还开发了多种在线工具,如BLAST(基本局部对齐search工具),用于比较生物序列,当你只有一段DNA、RNA或蛋白序列的时候,你想知道它是什么,这时候BLAST:Basic Local Alignment Search Tool (http://nih.gov)就是一个很好的工具,BLAST能够快速比较核酸或蛋白质之间的相似性,帮助你快速找到相似的基因或者蛋白。这些资源对于研究人员、医生、学生和公众来说都是免费可用的,极大地促进了生物医学研究和教育。
二、NCBI数据库怎么用呢?
NCBI数据库是一个提供广泛生物医学信息的综合资源库,涵盖了基因、RNA、蛋白质序列等多个领域。NCBI收录了70000多种生物的核苷酸序列,每条纪录都有编码区(CDS)特征的注释,还包括氨基酸的翻译。与专注于基因组检索的Ensembl数据库相比,NCBI的数据库内容更为广泛和综合。NCBI提供了多达36种不同的数据检索及分析工具,其主页面显示了不同的功能分区,以下是一个简要的使用教程:
1.访问NCBI官网:首先,打开浏览器并输入http://www.ncbi.nlm.nih.gov,进入NCBI的主页。
2.search文献:在主页的search框中输入您感兴趣的关键词,例如疾病名称、基因名称或特定的生物化学物质等。点击“Search”按钮进行search。
3.浏览search结果:search结果会列出相关的文献、基因、蛋白质等信息。您可以点击相应的链接查看详细信息。
4.使用PubMed:PubMed是NCBI提供的一个免费的文献检索系统。在主页上点击“PubMed”链接,进入PubMed search界面。您可以使用布尔运算符(AND,OR,NOT)来组合关键词进行更精确的search。
5.查找基因信息:在主页上点击“Gene”链接,进入基因数据库。在这里您可以search特定的基因,并获取其序列、功能、表达等信息。
6.查找蛋白质信息:点击“Protein”链接,进入蛋白质数据库。您可以search特定的蛋白质,了解其结构、功能、相互作用等信息。
7.使用BLAST:在主页上点击“BLAST”链接,选择合适的BLAST程序进行序列比对。
8.注册账号:为了使用一些高级功能,如保存search历史、创建个性化的工作区等,您可以在主页上注册一个NCBI账号。
9.学习资源:NCBI提供了许多学习资源,包括教程、视频、FAQ等,帮助用户更好地使用数据库。您可以在主页上找到这些资源。
三、如何查找CDS和蛋白序列?
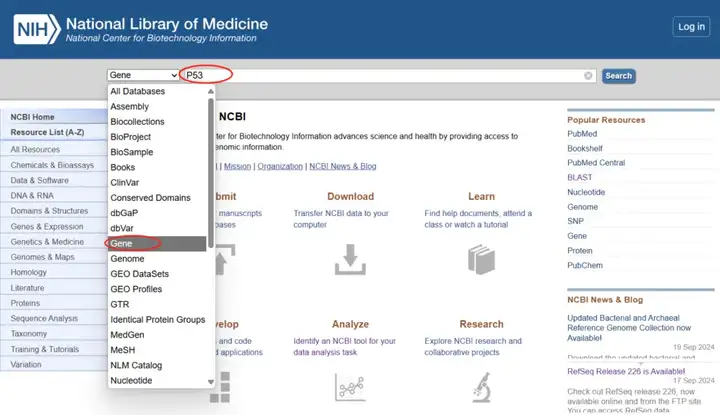
进入NCBI网站,选择“Gene”,在search框中输入感兴趣的基因的名称、基因ID或相关的生物物种,以“P53”为例。
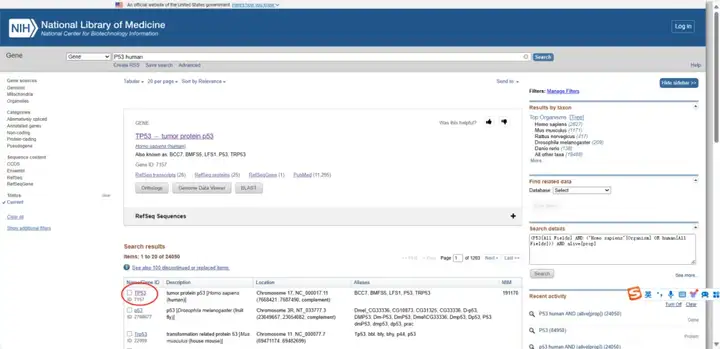
点击“search”按钮,系统会显示与您的查询相关的数据库条目列表,选择对应的物种,以“human”为例。
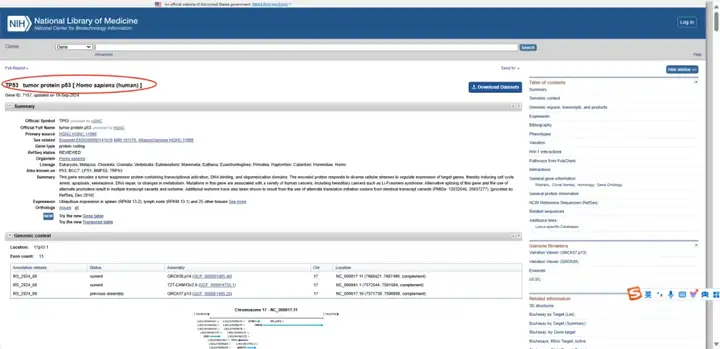
点击对应物种基因名,系统会显示与您的查询相关的数据库条目列表。包括基因的Summary、Genomic context和Genomic regions, transcripts, and products等。
在search结果中,找到“Genomic regions, transcripts, and products”条目,该页面显示了基因所有对应的转录本ID和蛋白ID,根据需求选择对应转录本,一般推荐MANE Select(MANE数据旨在收录和整理人类基因的转录本注释信息,并且提供编码基因最具代表性转录本和相应的蛋白质。)鼠标悬浮在转录本上,在转录本信息里可以看到“Status:MANE Select”。
另外,转录本的选择一般有两种思路,一种是一般认为每个基因在“NCBI Reference Sequences(RefSeq)”条目里显示的转录本1是研究最多的,可以从转录本编号后边的“.几”来判断该转录本更新的次数,更新的次数越多代表该转录本研究的越多;另一种则是选择众多mRNA转录本中最长的转录本(longest isoform)。
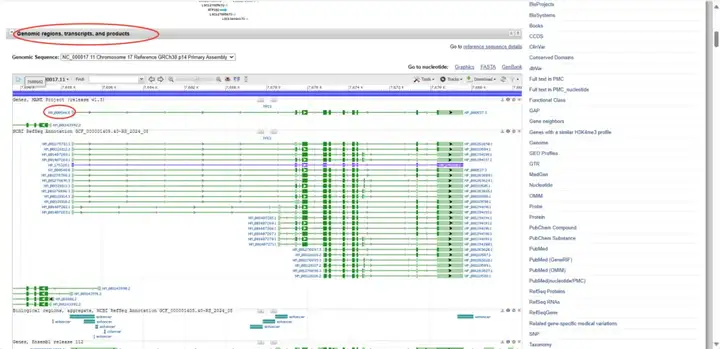
鼠标悬浮在第一个转录本上,会出现该转录本的详细信息,如Location:complement(7,668,421..7,687,490)、CDS length:1182 nt和Protein length:393 aa等。
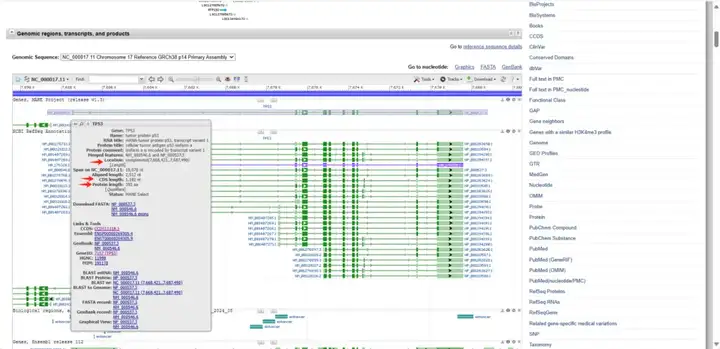
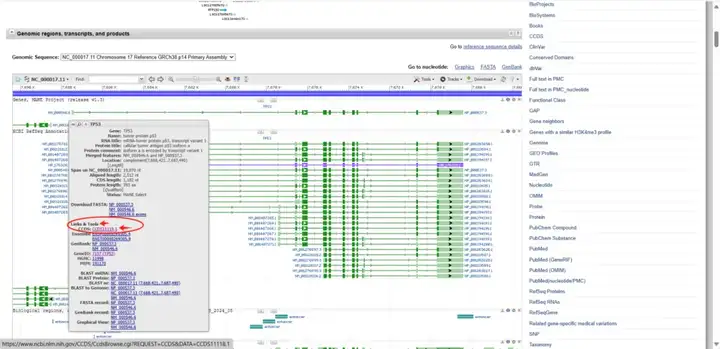
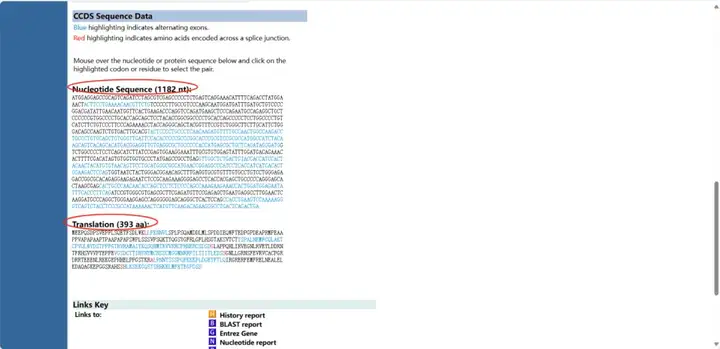
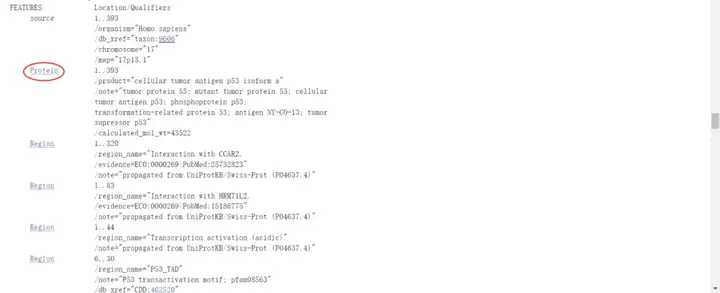
您可以在页面上找到“Links & Tools”条目,点击“CCDS:CCDS11118.1”,进入相应的详细页面,找到“Nucleotide Sequence(1182 nt)即CDS序列”,找到“Translation(393 aa)即蛋白序列”。
另外,在基因相关信息页面,下拉找到“NCBI Reference Sequences(RefSeq)”条目,在“mRNA and Protein(s)”里可以看到有不同的转录本,其中mRNA一般是“NM”开头,非编码RNA一般以“NR”开头,还有一种“XM”开头是生物信息预测的转录本。“NP”开头表示蛋白质,“NC”开头表示基因。
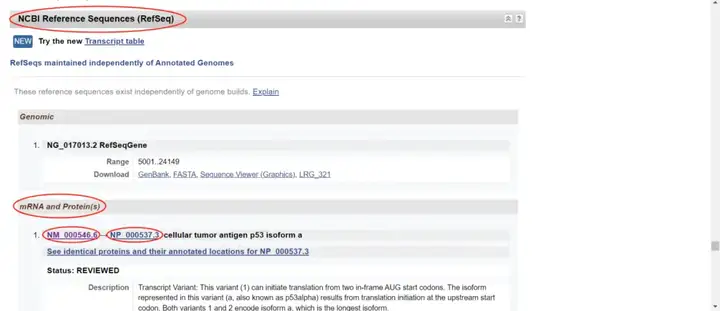
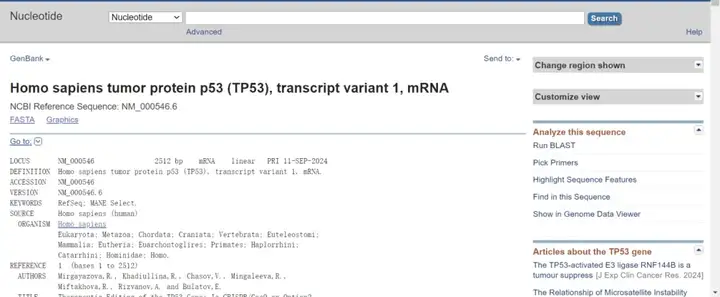
找到想要的“NM”开头的转录本号和“NP”开头的蛋白号,点击进入,即可看到基因详细信息。
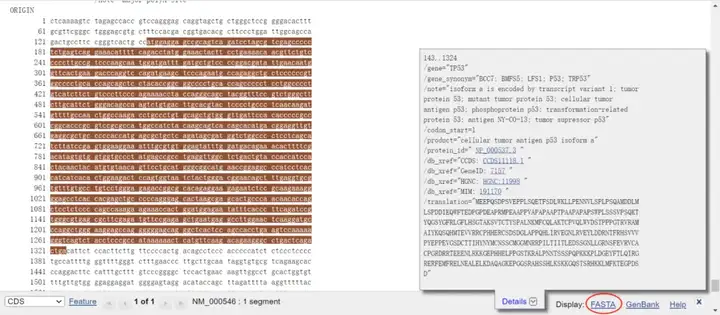
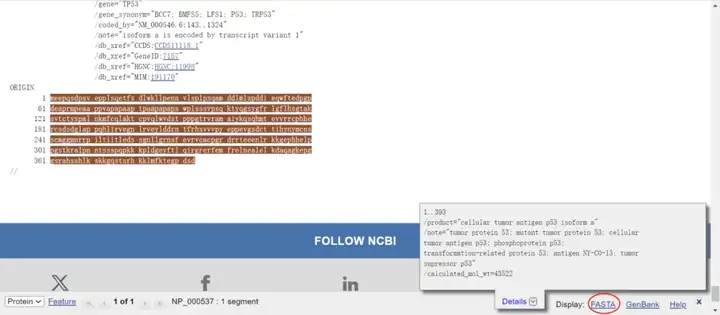
下滑找到“CDS”,点击,即可看到CDS序列,可以直接复制或者点击右下角“FASTA”再复制。

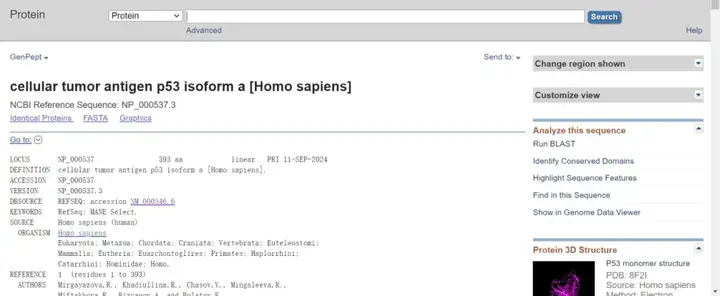
蛋白序列同理,下滑找到“Protein”,点击即可直接复制或者点击右下角“FASTA”再复制。
四、如何查找启动子序列?
进入NCBI网站,选择“Gene”,在search框中输入感兴趣的基因的名称、基因ID或相关的生物物种,以“P53”为例。
点击“search”按钮,系统会显示与您的查询相关的数据库条目列表,选择对应的物种,以“human”为例。
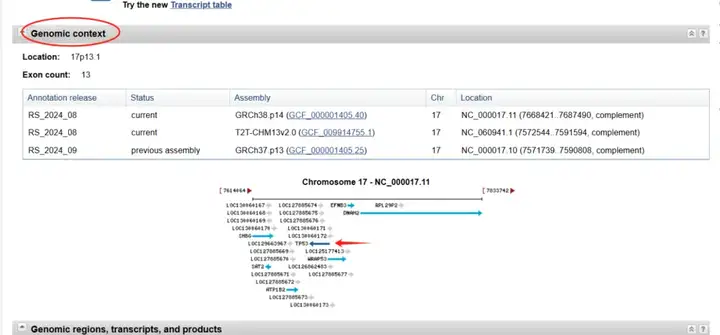
向下翻动页面,找到“Genomic context”条目,此时注意查看基因的方向,P53基因方向为反向。
向下翻动页面,找到“Genomic regions, transcripts, and products”条目,点击FASTA。
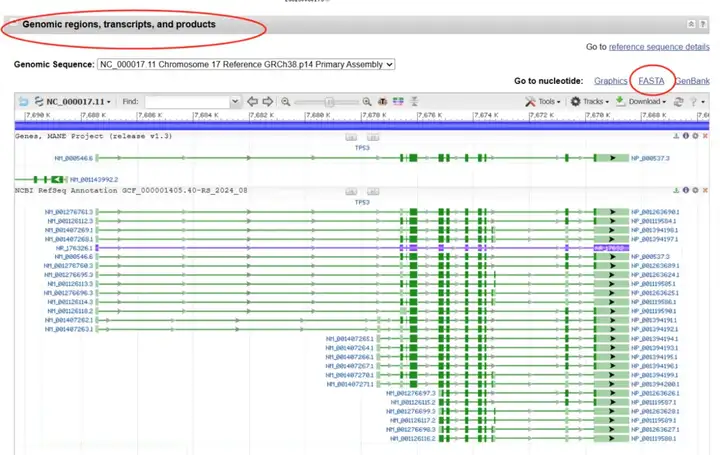
进入基因序列详情页,在右侧“Selected region”选项中把from7668421to7687490改为from7687491to7689491(启动子序列一般默认为基因上游2000bp,由于P53基因方向为反向,而NCBI默认的基因方向为正向,故选择在基因位置最大值上加2001,若基因方向为正向,则选择在基因位置最小值上减2001)。
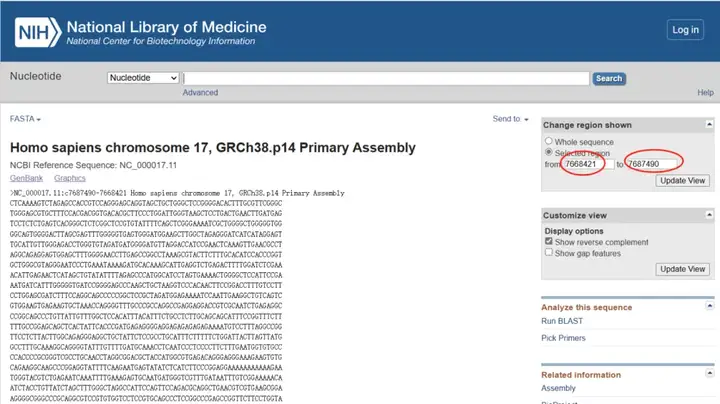
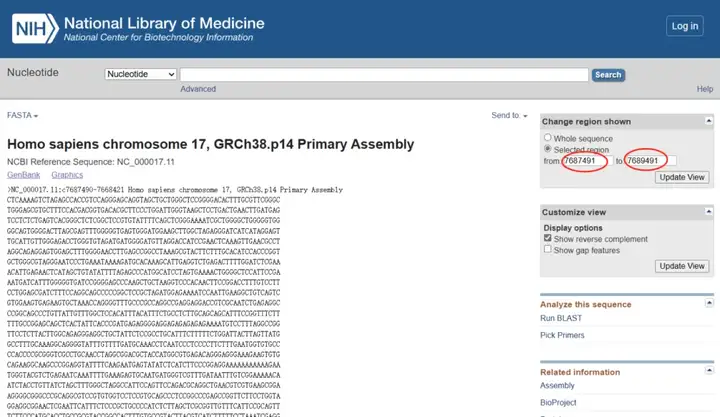
点击“Update View”,所得序列即为P53基因启动子区域序列。
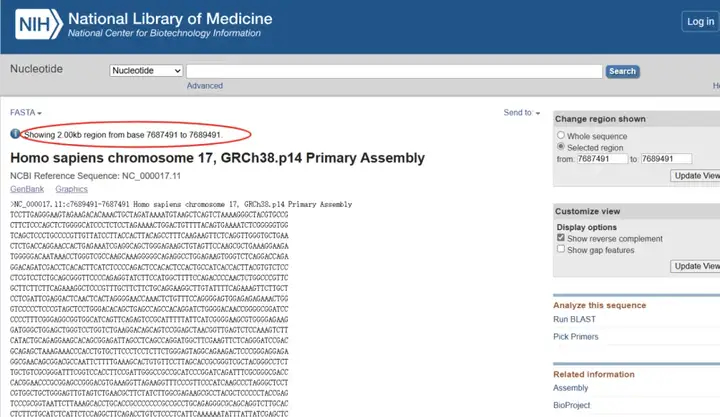
五、如何查找基因的5’UTR和3’UTR序列?
进入NCBI网站,选择“Gene”,在search框中输入感兴趣的基因的名称、基因ID或相关的生物物种,以“GAPDH”为例。
点击“search”按钮,系统会显示与您的查询相关的数据库条目列表,选择对应的物种,以“human”为例。
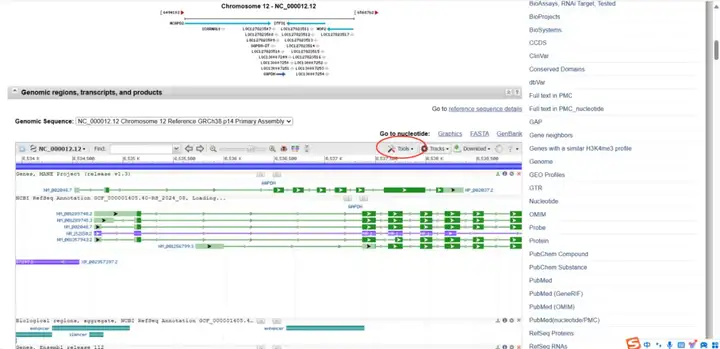
向下翻动页面,找到“Genomic regions, transcripts, and products”条目,点击“Tools”。
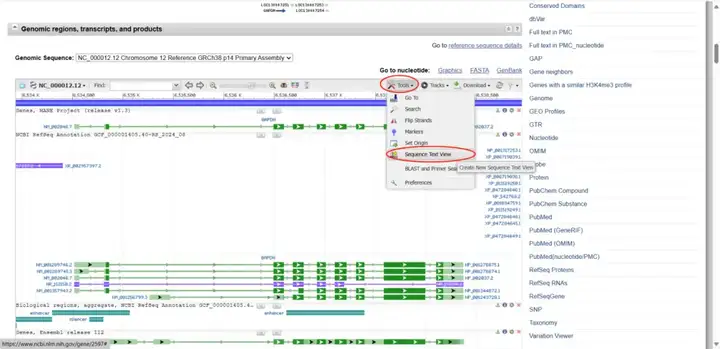
选择“Tools”中的“sequence text view”选项,点击后能看到基因的序列信息。
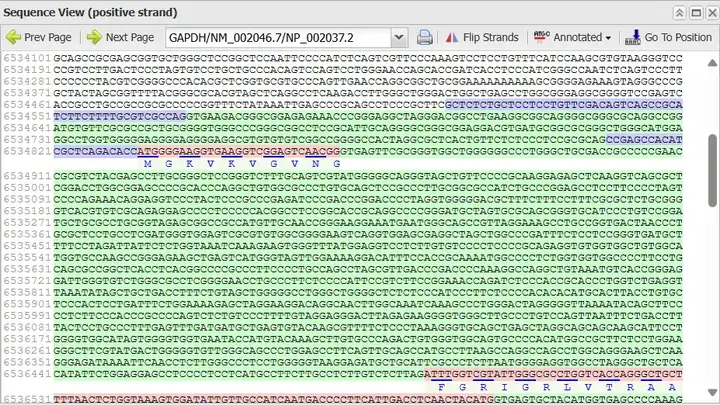
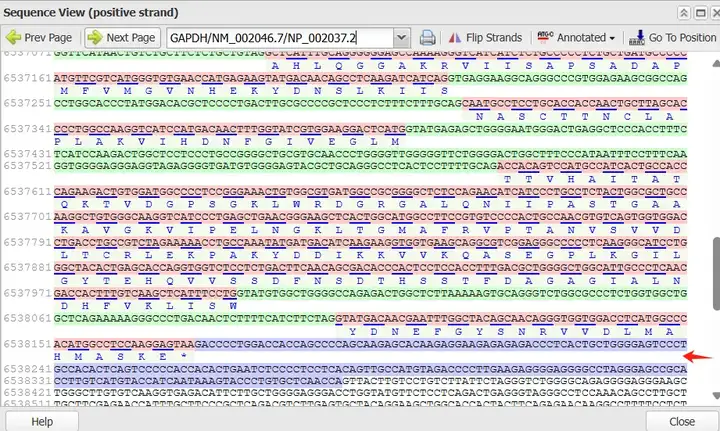
显示出来的结果应该怎么看?(这里标记的颜色是网站自动给出来的。)
蓝色标记序列代表的是5’UTR或3’UTR。红色标记序列代表的是外显子,因为外显子要翻译成氨基酸,所以下面会给出对应的氨基酸序列。绿色标记序列代表的是内含子,内含子不翻译,所以下面没有氨基酸序列。若没有显示出来完整的5’UTR或3’UTR,可以点左上角的“Prev page”或“Next page”。
因此,GAPDH这个基因的5’UTR序列如下:
GCTCTCTGCTCCTCCTGTTCGACAGTCAGCCGCATCTTCTTTTGCGTCGCCAG
3’UTR序列如下:
GACCCCTGGACCACCAGCCCCAGCAAGAGCACAAGAGGAAGAGAGAGACCCTCACTGCTGGGGAGTCCCTGCCACACTCAGTCCCCCACCACACTGAATCTCCCCTCCTCACAGTTGCCATGTAGACCCCTTGAAGAGGGGAGGGGCCTAGGGAGCCGCACCTTGTCATGTACCATCAATAAAGTACCCTGTGCTCAACCA
六、如何查找lncRNA序列?
进入NCBI网站,选择“Gene”,在search框中输入感兴趣的lncRNA名称、基因ID或相关的生物物种,以“MALAT1”为例。
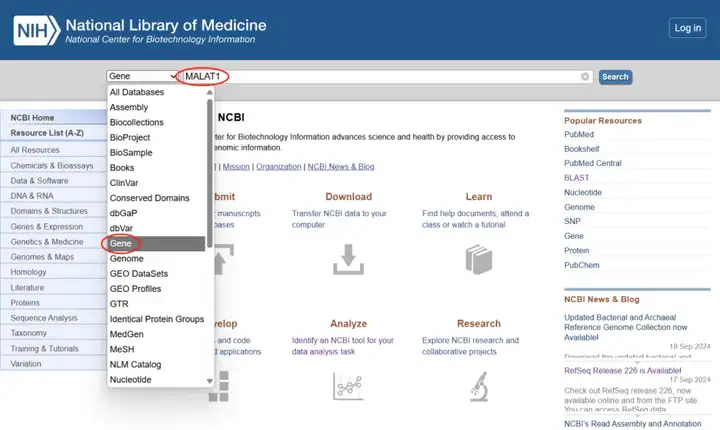
点击“search”按钮,系统会显示与您的查询相关的数据库条目列表,选择对应的物种,以“human”为例。
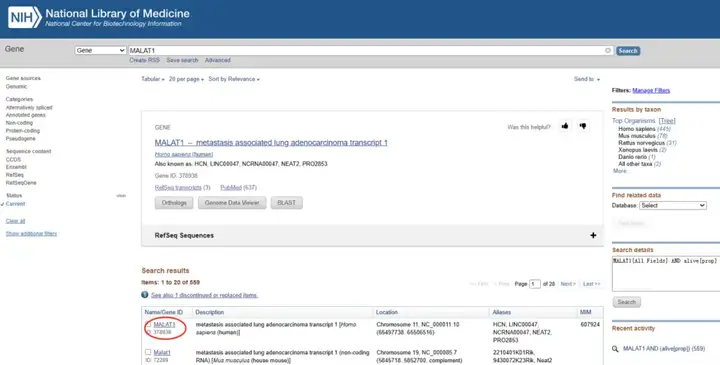
向下翻动页面,找到“NCBI Reference Sequences(RefSeq)”条目,在“RNA”里可以看到有很多转录本,根据需求选择对应的转录本,一般推荐RefSeq Select(RefSeq的Select转录本通常有良好的存档数据支持,表达良好,保守,代表基因的生物学特性。)
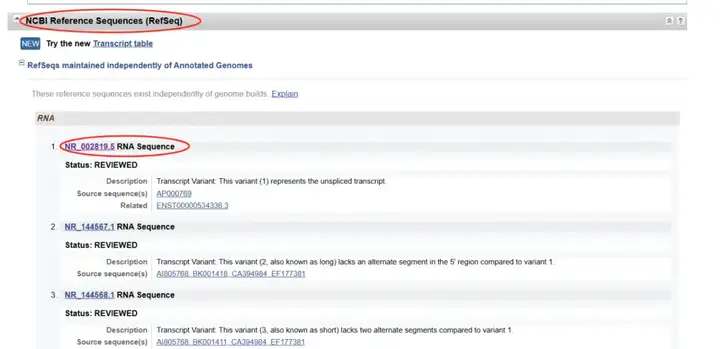
向下翻动页面,找到“gene”条目点击,所得序列即为lncRNA“MALAT1”的序列。

